August 2023
Benchmarks für ChatGPT & Co:
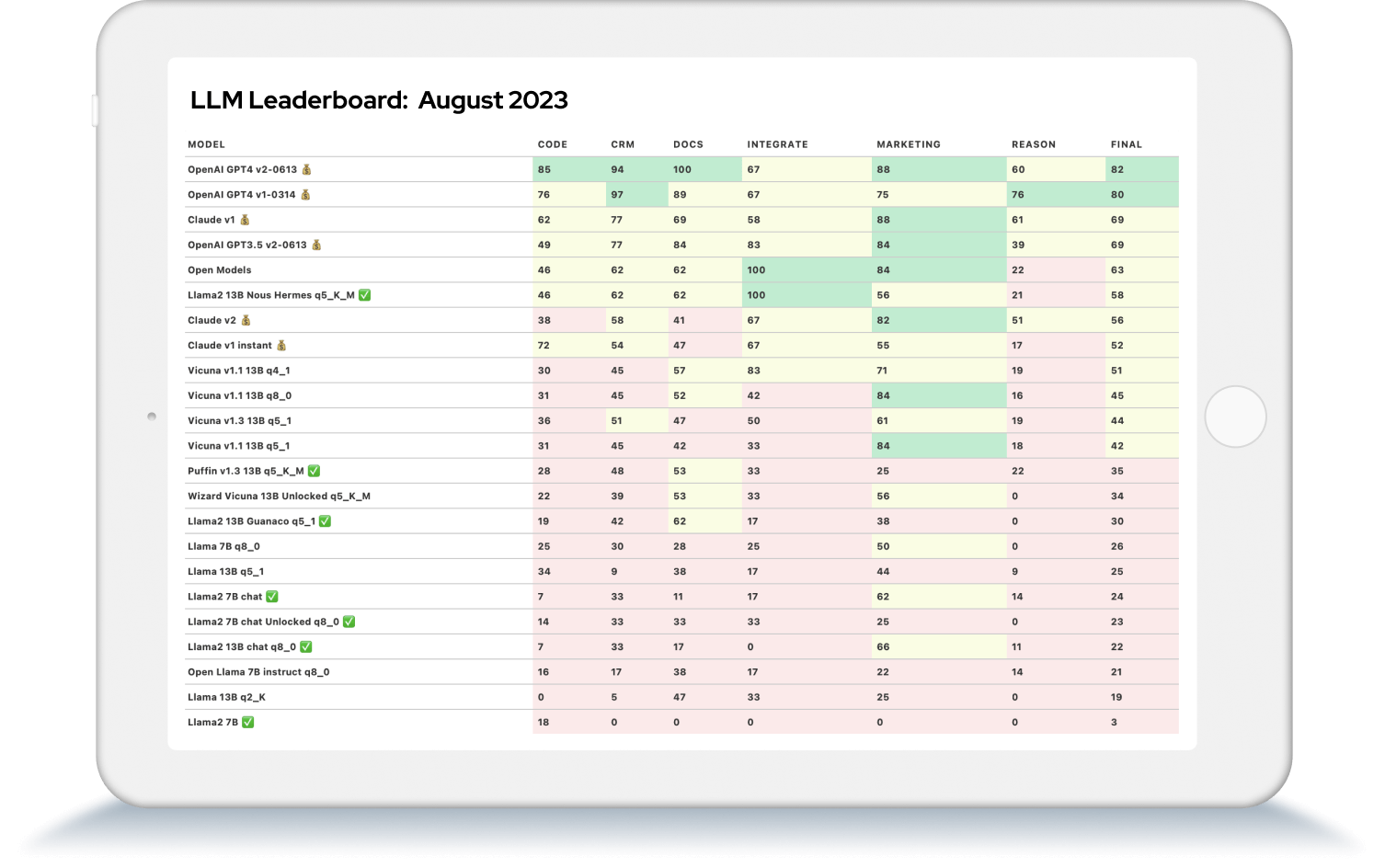

Monatlich aktualisiert: Das Trustbit LLM Leaderboard bietet Ihnen einen aktuellen Vergleich verschiedener Large Language Models wie ChatGPT und mehr, um deren Eignung für den Einsatz in der Produktentwicklung zu bewerten.
Trustbit Leaderboard
August 2023
| model | code | crm | docs | integrate | marketing | reason | final |
|---|---|---|---|---|---|---|---|
| OpenAI GPT4 v2-0613 💰 | 85 | 94 | 100 | 67 | 88 | 60 | 82 |
| OpenAI GPT4 v1-0314 💰 | 76 | 97 | 89 | 67 | 75 | 76 | 80 |
| Claude v1 💰 | 62 | 77 | 69 | 58 | 88 | 61 | 69 |
| OpenAI GPT3.5 v2-0613 💰 | 49 | 77 | 84 | 83 | 84 | 39 | 69 |
| Open Models | 46 | 62 | 62 | 100 | 84 | 22 | 63 |
| Llama2 13B Nous Hermes q5_K_M ✅ | 46 | 62 | 62 | 100 | 56 | 21 | 58 |
| Claude v2 💰 | 38 | 58 | 41 | 67 | 82 | 51 | 56 |
| Claude v1 instant 💰 | 72 | 54 | 47 | 67 | 55 | 17 | 52 |
| Vicuna v1.1 13B q4_1 | 30 | 45 | 57 | 83 | 71 | 19 | 51 |
| Vicuna v1.1 13B q8_0 | 31 | 45 | 52 | 42 | 84 | 16 | 45 |
| Vicuna v1.3 13B q5_1 | 36 | 51 | 47 | 50 | 61 | 19 | 44 |
| Vicuna v1.1 13B q5_1 | 31 | 45 | 42 | 33 | 84 | 18 | 42 |
| Puffin v1.3 13B q5_K_M ✅ | 28 | 48 | 53 | 33 | 25 | 22 | 35 |
| Wizard Vicuna 13B Unlocked q5_K_M | 22 | 39 | 53 | 33 | 56 | 0 | 34 |
| Llama2 13B Guanaco q5_1 ✅ | 19 | 42 | 62 | 17 | 38 | 0 | 30 |
| Llama 7B q8_0 | 25 | 30 | 28 | 25 | 50 | 0 | 26 |
| Llama 13B q5_1 | 34 | 9 | 38 | 17 | 44 | 9 | 25 |
| Llama2 7B chat ✅ | 7 | 33 | 11 | 17 | 62 | 14 | 24 |
| Llama2 7B chat Unlocked q8_0 ✅ | 14 | 33 | 33 | 33 | 25 | 0 | 23 |
| Llama2 13B chat q8_0 ✅ | 7 | 33 | 17 | 0 | 66 | 11 | 22 |
| Open Llama 7B instruct q8_0 | 16 | 17 | 38 | 17 | 22 | 14 | 21 |
| Llama 13B q2_K | 0 | 5 | 47 | 33 | 25 | 0 | 19 |
| Llama2 7B ✅ | 18 | 0 | 0 | 0 | 0 | 0 | 3 |
Die Benchmark-Kategorien im Detail
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
Neuste Versionen von ChatGPT, Anthropic Claude und Meta LlaMA auf dem Markt
Seit der Veröffentlichung des Trustbit Juli-Rankings gab es mehrere interessante Neuheiten.
OpenAI hat neue Versionen von ChatGPT (v0613) herausgebracht, die Effizienzsteigerungen und JavaScript-function calling conventions bieten.
Anthropic hat die zweite Ausgabe von Claude veröffentlicht - den engsten kommerziellen Konkurrenten von OpenAI ChatGPT.
Meta hat die zweite Generation von LLaMA - Llama v2 - eingeführt.
Jede dieser Veröffentlichungen verspricht bedeutsame Verbesserungen in den Fähigkeiten großer Sprachmodelle. Wir haben für Sie analysiert, ob sich ein Upgrade jedoch wirklich lohnt und was es zu beachten gibt.
OpenAI ChatGPT-4 0613: kann upgegradet werden
In unseren Tests schneidet die neue Version von ChatGPT-4 etwas besser ab als die vorherige Version. Sie hat einen spürbaren Geschwindigkeitsschub erhalten, die Leistung bei Aufgaben im Zusammenhang mit Code und Marketing hat sich signifikant verbessert. Allerdings ist gleichzeitig die Fähigkeit zur Schlussfolgerung und zur Arbeit mit Dokumenten leicht gesunken.
Wenn Sie die bestmögliche Leistung von Ihrem wissensorientierten Unternehmensassistenten herausholen möchten, könnte es sich lohnen, bei der Migration vorsichtig vorzugehen.
Anthropic Claude v2 hat in unseren Tests spürbar schlechter abgeschnitten. Es scheint, als wäre er darauf abgestimmt worden, ein besseres Chat-Bot zu sein, auf Kosten der Produktfähigkeiten.
Wenn möglich, empfehlen wir, Claude v1 weiterhin zu verwenden, bis die zweite Version sich weiter verbessert.
Anthropic Claude v2:
nicht upgraden
Meta Llama v2:
upgrade empfohlen
Das Llama v2-Modell ist ein offenes Modell von Meta (Facebook) mit einer kommerziell großzügigen Lizenz. Diese Lizenz macht das Modell endlich für ernsthafte Projekte nutzbar.
Llama v2 sollte ein besseres Modell sein. Allerdings performt das Basismodell signifikant schlechter als das Basismodell von v1. Die Hauptursache dafür ist, dass es ebenfalls zu gesprächig ist und sensibel auf Promts reagiert. Das Basismodell dominiert die unteren Ränge unserer Rangliste.
Doch bei offenen Modellen bedeuten schlechte Ergebnisse nicht das Ende der Geschichte. Sie können von der Community weiter trainiert werden.
Nous Research hat ihre eigene feinabgestimmte Version von Llama v2 veröffentlicht, die Nous Hermes genannt wird. Hermes übertrifft nicht nur Vicuna, sondern holt auch Claude v2 ein.
Was ist ein Leaderboard?
Ein Leaderboard ist eine Rangliste oder Tabelle, die verschiedene Elemente, Personen oder Produkte basierend auf bestimmten Kriterien miteinander vergleicht und ordnet. Es dient dazu, eine übersichtliche Darstellung der Leistung oder Eigenschaften der aufgeführten Elemente zu bieten und ermöglicht es den Betrachtern, schnell zu erkennen, welche Elemente an der Spitze stehen oder am besten abschneiden.
Wobei hilft mir das Trustbit LLM Leaderboard?
Das LLM Leaderboard von Trustbit hilft Ihnen dabei, das aktuell optimalste Large Language Model für den Einsatz im Bereich Produktentwicklung zu finden. Die von uns erstellte Scoring-Liste basiert auf realen Benchmarks, die wir aus von uns entwickelten Softwareprodukten extrahiert haben. Sie bewertet die Fähigkeiten der verschiedenen LLM-Modelle, spezifische Aufgaben in der Produktentwicklung zu erfüllen.
Welche Kategorien werden verglichen?
Folgende Kategorien stehen Ihnen zur Verfügung, um die Fähigkeiten der unterschiedlichen Modelle zu bewerten:
Dokumente: Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
CRM: Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
Integration: Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
Marketing: Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
Schlussfolgerungen: Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
Code: Kann das Modell Code generieren und bei der Programmierung helfen?