November 2023
Benchmarks für ChatGPT & Co:

Diese November-Benchmarks bewerten GPT-4 Turbo, das neueste GPT3.5 und stellt Mistral OpenChat 7B vor.
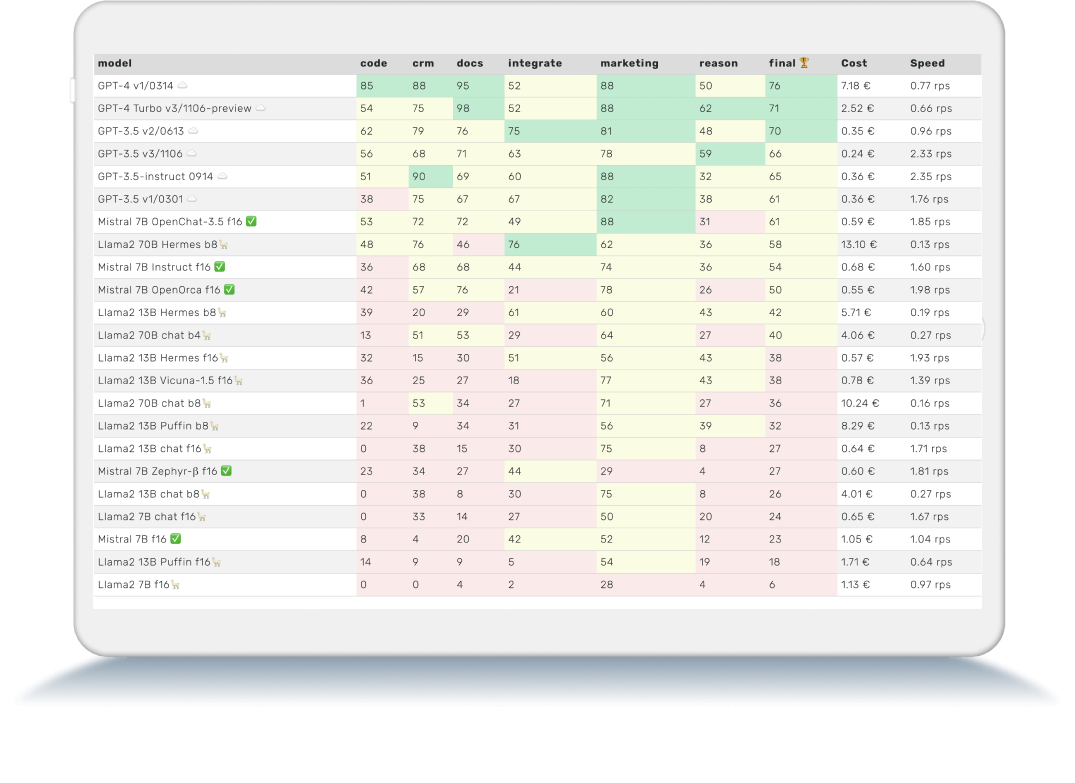
Trustbit Leaderboard November 2023
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
☁️ - Cloud-Modelle mit proprietärer Lizenz
✅ - Open-Source-Modelle, die lokal ohne Einschränkungen ausgeführt werden können
🦙 - Lokale Modelle mit Llama2-Lizenz
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 85 | 88 | 95 | 52 | 88 | 50 | 76 | 7.18 € | 0.77 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 54 | 75 | 98 | 52 | 88 | 62 | 71 | 2.52 € | 0.66 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 76 | 75 | 81 | 48 | 70 | 0.35 € | 0.96 rps |
| GPT-3.5 v3/1106 ☁️ | 56 | 68 | 71 | 63 | 78 | 59 | 66 | 0.24 € | 2.33 rps |
| GPT-3.5-instruct 0914 ☁️ | 51 | 90 | 69 | 60 | 88 | 32 | 65 | 0.36 € | 2.35 rps |
| GPT-3.5 v1/0301 ☁️ | 38 | 75 | 67 | 67 | 82 | 38 | 61 | 0.36 € | 1.76 rps |
| Mistral 7B OpenChat-3.5 f16 ✅ | 53 | 72 | 72 | 49 | 88 | 31 | 61 | 0.59 € | 1.85 rps |
| Llama2 70B Hermes b8🦙 | 48 | 76 | 46 | 76 | 62 | 36 | 58 | 13.10 € | 0.13 rps |
| Mistral 7B Instruct f16 ✅ | 36 | 68 | 68 | 44 | 74 | 36 | 54 | 0.68 € | 1.60 rps |
| Mistral 7B OpenOrca f16 ✅ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.55 € | 1.98 rps |
| Llama2 13B Hermes b8🦙 | 39 | 20 | 29 | 61 | 60 | 43 | 42 | 5.71 € | 0.19 rps |
| Llama2 70B chat b4🦙 | 13 | 51 | 53 | 29 | 64 | 27 | 40 | 4.06 € | 0.27 rps |
| Llama2 13B Hermes f16🦙 | 32 | 15 | 30 | 51 | 56 | 43 | 38 | 0.57 € | 1.93 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 25 | 27 | 18 | 77 | 43 | 38 | 0.78 € | 1.39 rps |
| Llama2 70B chat b8🦙 | 1 | 53 | 34 | 27 | 71 | 27 | 36 | 10.24 € | 0.16 rps |
| Llama2 13B Puffin b8🦙 | 22 | 9 | 34 | 31 | 56 | 39 | 32 | 8.29 € | 0.13 rps |
| Llama2 13B chat f16🦙 | 0 | 38 | 15 | 30 | 75 | 8 | 27 | 0.64 € | 1.71 rps |
| Mistral 7B Zephyr-β f16 ✅ | 23 | 34 | 27 | 44 | 29 | 4 | 27 | 0.60 € | 1.81 rps |
| Llama2 13B chat b8🦙 | 0 | 38 | 8 | 30 | 75 | 8 | 26 | 4.01 € | 0.27 rps |
| Llama2 7B chat f16🦙 | 0 | 33 | 14 | 27 | 50 | 20 | 24 | 0.65 € | 1.67 rps |
| Mistral 7B f16 ✅ | 8 | 4 | 20 | 42 | 52 | 12 | 23 | 1.05 € | 1.04 rps |
| Llama2 13B Puffin f16🦙 | 14 | 9 | 9 | 5 | 54 | 19 | 18 | 1.71 € | 0.64 rps |
| Llama2 7B f16🦙 | 0 | 0 | 4 | 2 | 28 | 4 | 6 | 1.13 € | 0.97 rps |
Die Benchmark-Kategorien im Detail
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Bewertungen neuer ChatGPT Modelle
Wir haben neue Modelle bewertet, die kürzlich von OpenAI veröffentlicht wurden (eine Zusammenfassung ihrer Präsentation findet man hier)."
GPT-4 Turbo (“GPT-4 Turbo v3/1106-preview” in der Tabelle) ist günstiger und weniger leistungsfähig als die vorherige Version. Wir haben eine Qualitätsverschlechterung bei komplexen Programmieraufgaben und CRM-Aufgaben festgestellt, die auf wenigen Beispieltexten basieren.
Der neue GPT-3 Turbo (“GPT-3.5 v3/1106”) ist ebenfalls günstiger und wesentlich schneller als sein Vorgänger. Er ist jedoch auch weniger leistungsfähig als die vorherige Version. Die Verschlechterung der Modellfähigkeiten entspricht den größeren GPT-4-Modellen.
Positiv zu erwähnen ist allerdings, dass beide Modelle folgende Eigenschaften aufweisen:
Aktuellere Trainingsdaten
Bessere Fähigkeiten in der Kategorie des logischen Denkens

Bessere Sprachunterstützung im GPT-4 Turbo
Der GPT-4 Turbo hat eine versteckte Überraschung, über die OpenAI nirgendwo erwähnt hat.
Aus Erfahrung wissen wir, dass OpenAI-Sprachmodelle im Allgemeinen wirklich gut in Englisch sind. Sie können auch in Chinesisch, Deutsch, Spanisch und romanogermanischen Sprachen angemessen sein. Fragen an die Sprachmodelle in anderen Sprachen führen jedoch im Vergleich zu Fragen auf Englisch in der Regel zu sehr schlechten Ergebnissen. Je kleiner der Sprachumfang ist, desto weniger schriftliche Materialien stehen im Internet zur Verfügung, und desto schlechter sind die Ergebnisse.
Hier glänzt der GPT-4 Turbo plötzlich. Experten, die mit ML in Nischensprachen arbeiten, berichten, dass ChatGPT nicht nur wesentlich besser darin ist, in kleinen Sprachen zu kommunizieren, sondern auch ein tieferes Verständnis für die zugehörige Geschichte und Kultur zeigt.
Das sind großartige Neuigkeiten für die Sprachmodelle! Doch damit hören sie nicht auf.
Mistral 7B OpenChat holt auf und zieht mit ChatGPT 3 gleich
In den Oktober-LLM Benchmarks haben wir ein neues Open-Source-Modell namens Mistral 7B vorgestellt. Es war für seine Größe ausreichend, lag jedoch immer noch unter Llama2 70B Hermes und ChatGPT. Hier ein Auszug aus den Oktober-Benchmarks:

Die November-Benchmarks stellen eine neue Variante von Mistral 7B namens Mistral 7B OpenChat vor. Es übertrifft Llama 70B Hermes und zieht mit ChatGPT 3.5 (der ersten Version) gleich.
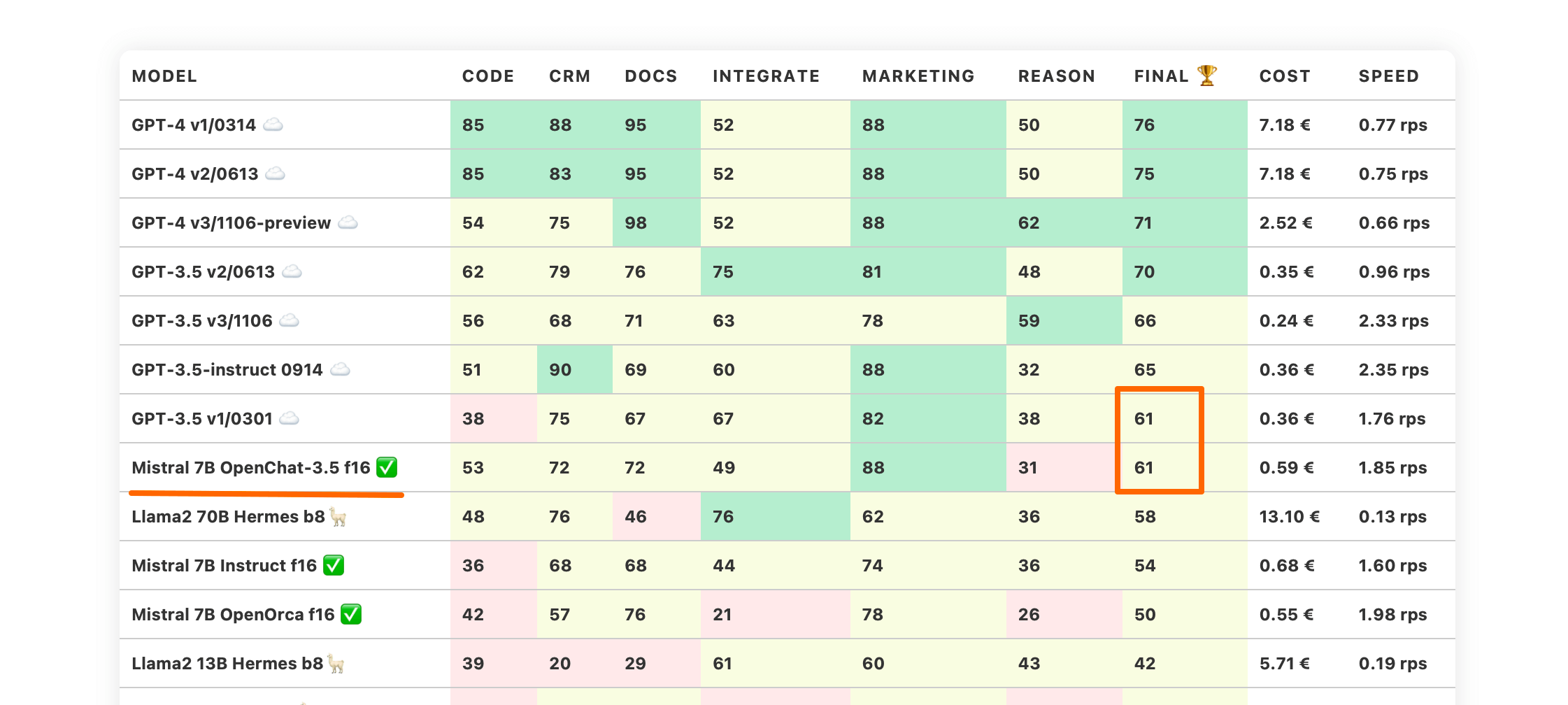
Der beeindruckendste Aspekt dieses Modells ist seine geringe Größe von lediglich 7B, wodurch es problemlos auf einfacher Standard-Hardware betrieben werden kann.
Zum Beispiel konnten wir bei einer Aufgabe zur Generierung von Suchbegriffen für Produktkataloge 10-15 Produkte pro Sekunde verarbeiten. Das alles auf einem Server mit einer NVidia 3090 GPU mit vLLM.
Mistral 7B OpenChat wäre auch besonders interessant für Unternehmen, die über gute LLM-Fähigkeiten verfügen möchten, aber nicht von der Betriebszeit der OpenAI-Services abhängig sein wollen (sie hatten kürzlich Ausfälle).
Beam Search verbessert die Genauigkeit von Sprachmodellen
Bei genauerem Vergleich unserer vorherigen Benchmarks mit den November-Benchmarks würde man feststellen, dass kleinere lokale Modelle "plötzlich" 4-5 Genauigkeitspunkte gewonnen haben. Wir haben die Beam-Search-Optimierung aktiviert. Dieser Algorithmus bewertet automatisch mehrere Antwortoptionen, bevor er die beste auswählt.
Diese Optimierung wird ab sofort für alle lokalen Modelle aktiviert sein. Später planen wir, den besten Branchenpraktiken zu folgen und noch mehr Varianten von Hilfestellungen in den Benchmark einzuführen.
Trustbit LLM Benchmarks Archiv

Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!