Part 1: Detecting Truck Parking Lots on Satellite Images
This post describes a student group project developed within the Data Science Lab undergraduate course of the Vienna University of Economics and Business, co-supervised by Trustbit.
Student project team: Michael Fixl, Josef Hinterleitner, Felix Krause and Adrian Seiß
Supervisors: Prof. Dr. Axel Polleres (WU Vienna), Dr. Vadim Savenkov (Trustbit)
Introduction
Real-time truck tracking is crucial in logistics: to enable accurate planning and provide reliable estimation of delivery times, operators build detailed profiles of loading stations, providing expected durations of truck loading and unloading, as well as resting times. Yet, how to derive an exact truck status based on mere GPS signals? Knowing the exact position and shape of truck parking lots can be advantageous in order to find out whether a truck is performing a loading action, or is just waiting nearby. Oftentimes, however, truck parking lots are not entirely recorded. In this post we describe a machine learning approach of detecting parking lot shapes based on satellite images. If you would like to check out details of the project or want to reproduce it, the code can be found on GitHub.
Building a dataset
Our first task is to obtain an annotated dataset of satellite images, so we resort to open data from OpenStreetMap to get both imagery and parking lot annotations, via the open dataset published by Google in BigQuery. In order to increase sample size, we make use of two satellite imagery sources from different timepoints and hence containing different image information. As you can see in the samples below, the images of the same parking lot differ in resolution as well as in time of recording (visible for example via the tree size in the center of the image). Thus, we can use almost all filtered parking lot shape annotations (below in blue) twice. Finally, a dataset of slightly above 1000 satellite images of truck parking lots with corresponding parking lot shape data is ready to be used for training models.


The approach
With the training data at hand, we create a model capable of predicting the exact shape of parking lots. We approach this task by using segmentation techniques. These methods try to divide an image into subgroups of predefined classes, so-called segments. They take a matrix with the pixel’s RGB values of an image as input as well as a matrix with the label of each pixel for training (called the mask). After training, the model assigns every pixel of an image to an object class, finally returning a matrix with the predicted class of each pixel.

In the following we assess five commonly used image segmentation techniques: Mask R-CNN, U-Net, FPN, LinkNet and PSPNet. To simplify the task, we first train the models in a small baseline setting using a ResNet50 backbone with pre-trained weights, a sample of the full dataset and restricted training time. The “mean intersection over union” (mIoU) metric is used to compare the models. For each image, IoU is the ratio of the intersection of the predicted mask and the true parking area to their union, the final metric being then an average IoU value over the test image dataset.
Key findings of the comparison
Assessing Mask R-CNN
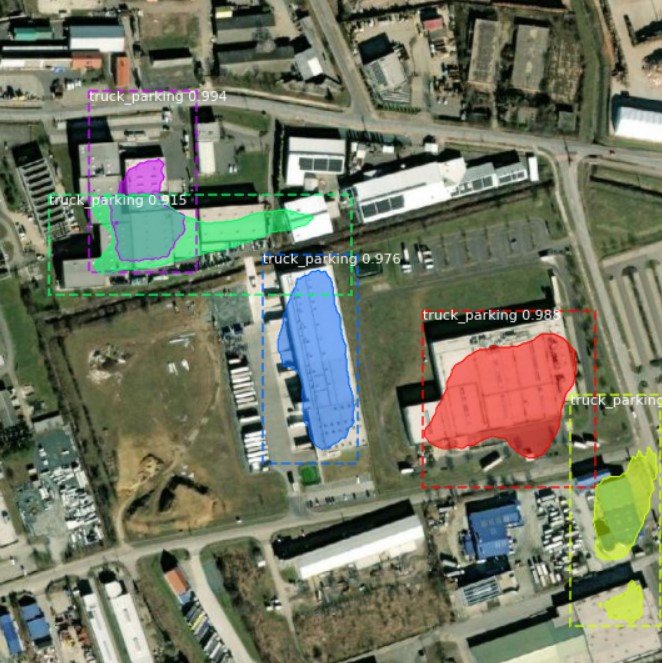
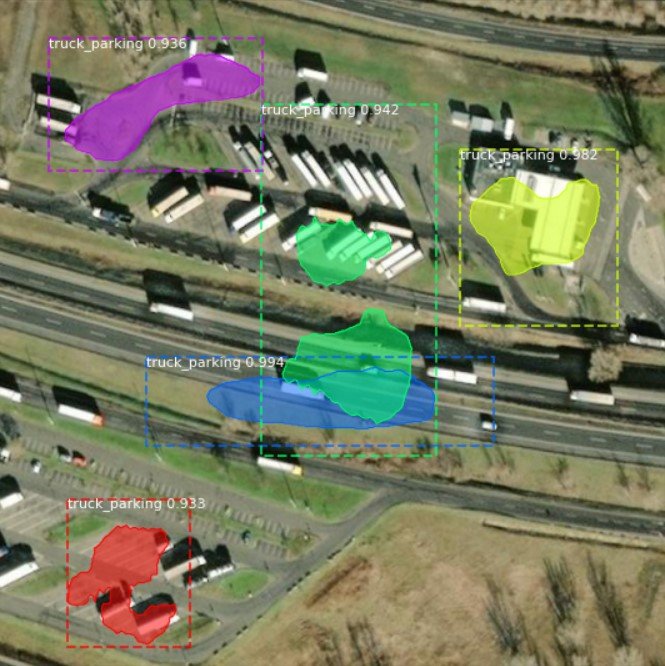
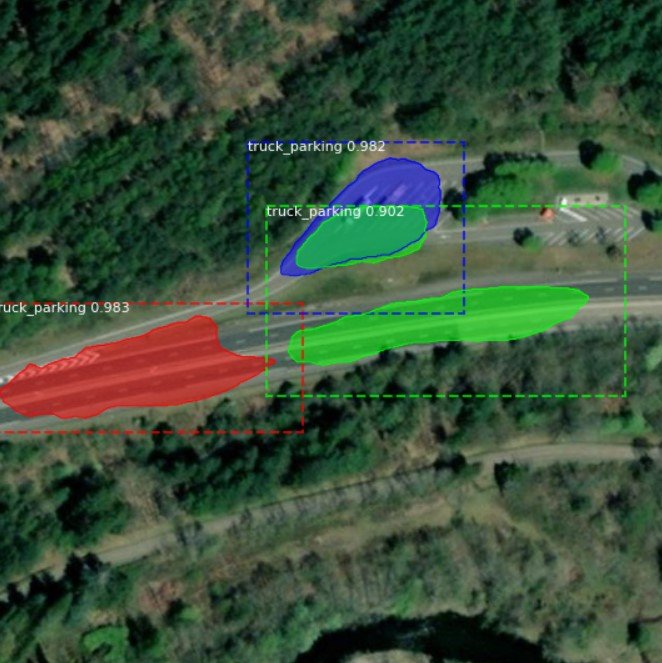
Our first candidate is Mask R-CNN. In contrast to other models in question, Mask R-CNN is able to identify each object instance of a particular type, rather than a union of all pixels belonging to a given class. You can see this ability in the images below, as every predicted parking lot has its own color.
As we can see in the samples, performance of this architecture was not very convincing for our task, while training also took up to seven times longer than for the algorithms following later on. The model often detects rooftops and streets as truck parking lots and frequently does not even recognize the true parking areas correctly. Expectably, the mIoU metric of approximately 26% is quite low, and therefore Mask R-CNN is not shortlisted for the final experiment. Let’s hope that other techniques produce better results for our problem.
Assessing semantic segmentation models
The remaining four models, namely U-Net, FPN, LinkNet and PSPNet, all belong to the class of semantic segmentation architectures. These architectures usually consist of an en- and decoder. While the encoder uses filters to extract features from an image, the decoder generates the final output, a mask of the predictions. The exact implementation and structure of en- and decoder differentiate the architectures mentioned and thus influence the final predictions [1].
Doing numerous test runs on Google Colab, the PSPNet architecture turned out to perform best. With a promising mIoU of 69% already in the baseline setting while also having a rather low training time of just a few minutes. The runner-up in our comparison was LinkNet with a mIoU of 65%, while the other two candidates FPN (58%) and U-Net (50%) demonstrated a noticeably lower performance.
Let’s now see what optimization of the PSPNet architecture can bring. Making use of additional data and hyperparameter tuning we can obtain a decent performance increase and reach a mIoU of 73.65%. This increase in prediction power is also clearly visible in the sample images below. Sometimes, however, the PSPNet model fails to recognize the parking area correctly, like in the rightmost image.



Conclusion
Overall, PSPNet showed stunning accuracy on the test set compared to the other algorithms tested. However, once we use out-of-sample data, we can see that performance is not very convincing. In the next blog post, we will thus try to increase generalizability and also test, if the code is easily transferable to other machines.
References:
[1] Source papers of U-Net: U-Net: Convolutional Networks for Biomedical Image Segmentation ,
FPN: Feature Pyramid Networks for Object Detection ,
LinkNet: LinkNet: Exploiting Encoder Representations for Efficient Semantic... ,
PSPNet: Pyramid Scene Parsing Network
Image sources:
Esri, Maxar, Earthstar Geographics, CNES/Airbus DS, and the GIS User Community